The
comprehensive energy-throughput comparisons of two
well-known asynchronous design styles applied to a
matrix-vector multiplication core of the discrete
cosine transforms (DCTs) is presented. The first
design style, bundled-data pipelines, uses a
single-rail synchronous datapath with recently
proposed true-four-phase controllers integrated with
data-dependent delay lines. The design achieves
reasonably-high average performance and very low
energy but requires significant design effort to
verify the two-sided timing constraints (set-up and
hold) typical of bundled-data pipelines. The second
design style, 2-D QDI pipelines, consists of a
network of small communicating cells communicating
through delay-insensitive 1-of-N encoded channels.
Compared to the bundled-data counterpart,
transistor-level simulations show that all QDI
designs achieve higher throughput at the cost of
larger area and energy and in particular have 22%
better Eτ2
metric. In addition, the QDI designs require less
design effort than the bundled-data counterpart,
because they require virtually no timing
verification.

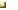 Bundled-data pipelines
Bundled-data pipelines
The
bundled-data pipelines or micropipelines, uses a
single-rail synchronous datapath with asynchronous
controllers driving novel speculative delay lines,
yielding low area, good average performance, and low
power. The cost of this design style, however, is
the significant increase in effort and risk
associated with verifying all the setup and hold
constraints typical of bundled-data design.
QDI
fine-grain 2-D pipelines
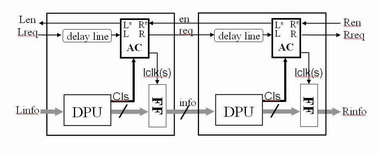
The
quasi-delay-insensitive (QDI) fine-grain 2-D
pipelines, has the advantages of robustness and high
throughput. In this design style, large functional
blocks are decomposed into small communicating cells
communicating through asynchronous channels. The
cells are implemented using the QDI design style
which means they will work correctly regardless of
wire delays except for very loose timing assumptions
on some internal wire forks. The asynchronous
channels use 1-of-N rail signaling providing
delay-insensitive communication. The cells are
arranged in a so-called 2-D pipeline that
facilitates very high-throughput independent of the
width of the datapath. The costs associate with this
design style compared to other asynchronous styles
is generally more area and higher absolute power
consumption.
Matrix-vector multiplication in the DCTs
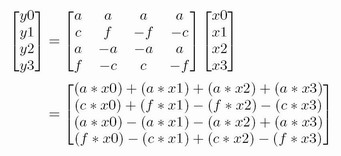
Our
matrix-vector multiplier is iterative. In each
iteration, it performs four multiply-accumulate
computations on constant coefficients and input
vectors X in order to generate one output vector Y .
In particular, the calculation is shown above where
a, c, and f are constant matrix coefficients.
Micro-architecture alternatives


